PAPER

Cross-Spectral Neural Radiance Fields
Matteo Poggi*, Pierluigi Zama Ramirez*, Fabio Tosi*, Samuele Salti, Stefano Mattoccia, Luigi Di Stefano
*Equal Contribution
Matteo Poggi*, Pierluigi Zama Ramirez*, Fabio Tosi*, Samuele Salti, Stefano Mattoccia, Luigi Di Stefano
*Equal Contribution
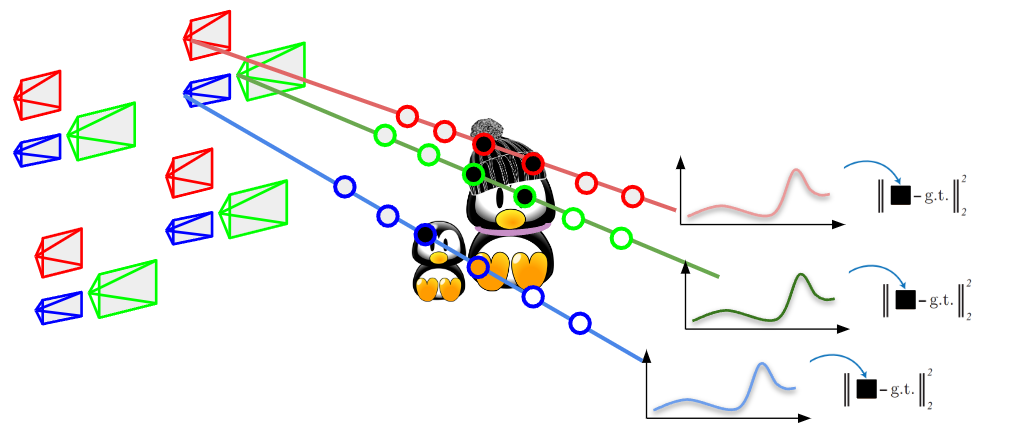
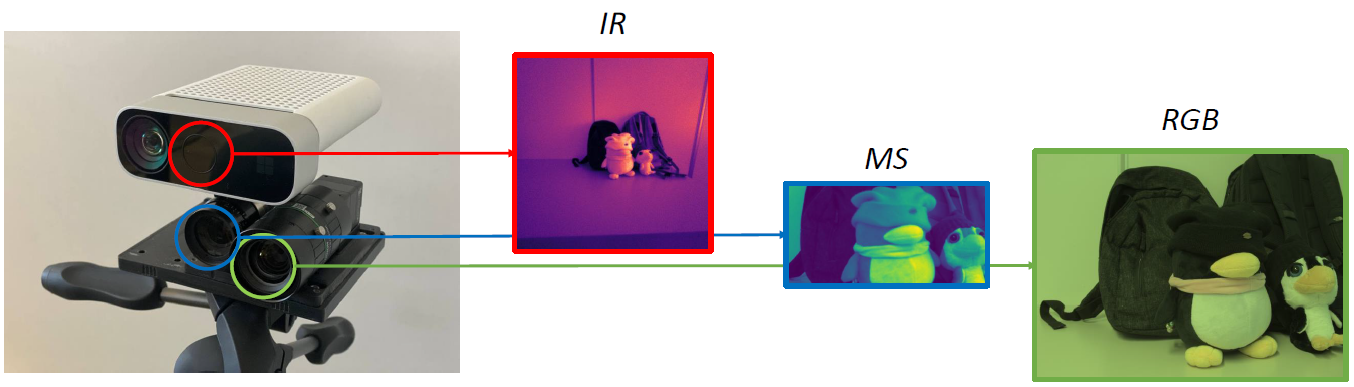
We propose X-NeRF, a novel method to learn a Cross-Spectral scene representation given images captured from cameras with different light spectrum sensitivity, based on the Neural Radiance Fields formulation. X-NeRF optimizes camera poses across spectra during training and exploits Normalized Cross-Device Coordinates (NXDC) to render images of different modalities from arbitrary viewpoints, which are aligned and at the same resolution. Experiments on 16 forward-facing scenes, featuring color, multi-spectral and infrared images, confirm the effectiveness of X-NeRF at modeling Cross-Spectral scene representations.
CITATION
@inproceedings{poggi2022xnerf,
title={Cross-Spectral Neural Radiance Fields},
author={Poggi, Matteo and Zama Ramirez, Pierluigi and Tosi, Fabio and Salti, Samuele and Di Stefano, Luigi and Mattoccia, Stefano},
booktitle={Proceedings of the International Conference on 3D Vision},
note={3DV},
year={2022},
}